14.1 设计需求
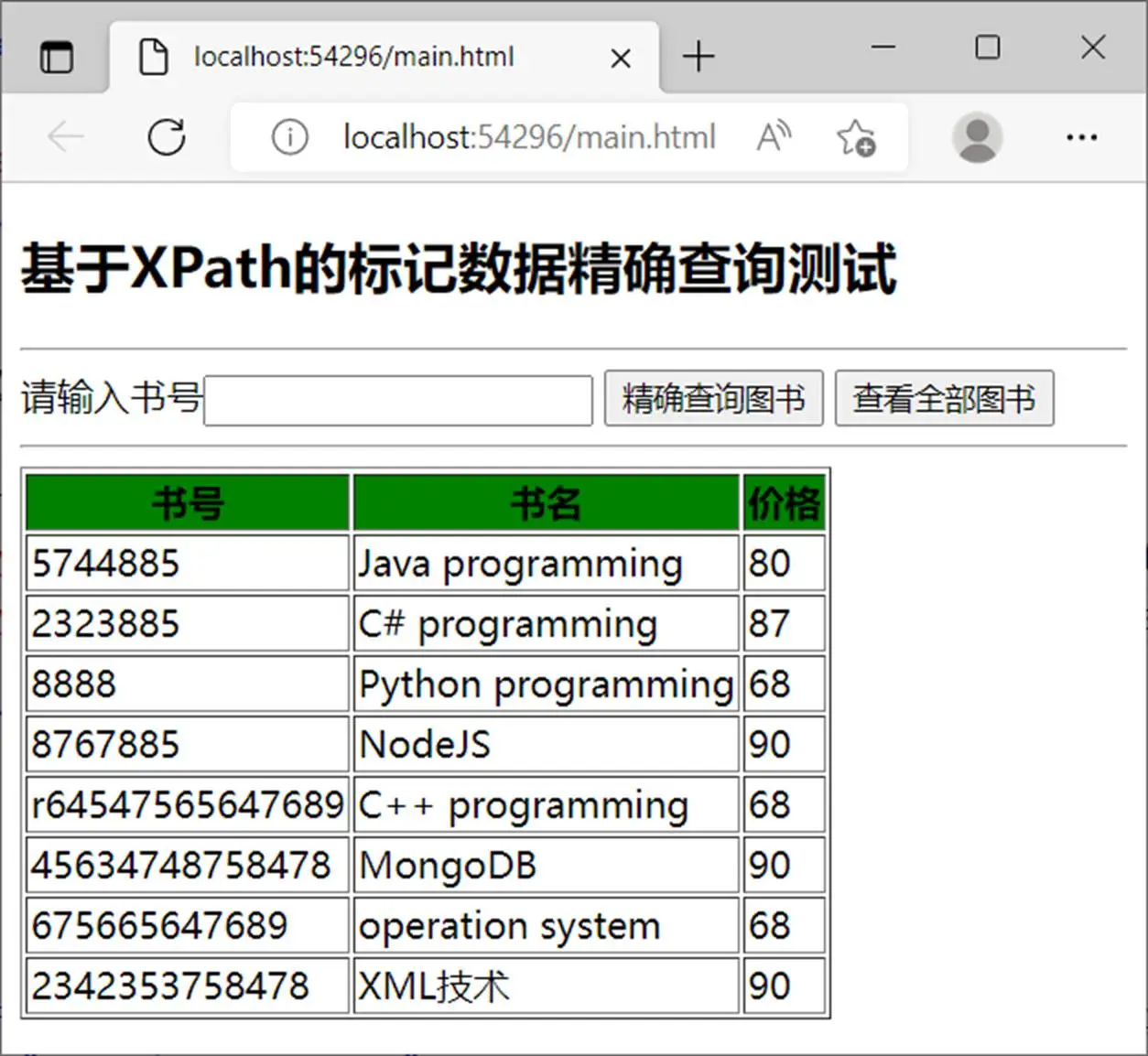
给定如下XML文档:
<?xml version="1.0" encoding="utf-8"?>
<table border="1" id="books">
<tr bgcolor="green">
<th id="ISBN">书号</th>
<th id="title">书名</th>
<th id="price">价格</th>
</tr>
<tr>
<td>5744885</td>
<td>Java programming</td>
<td>80</td>
</tr>
<tr>
<td>2323885</td>
<td>C# programming</td>
<td>87</td>
</tr>
<tr>
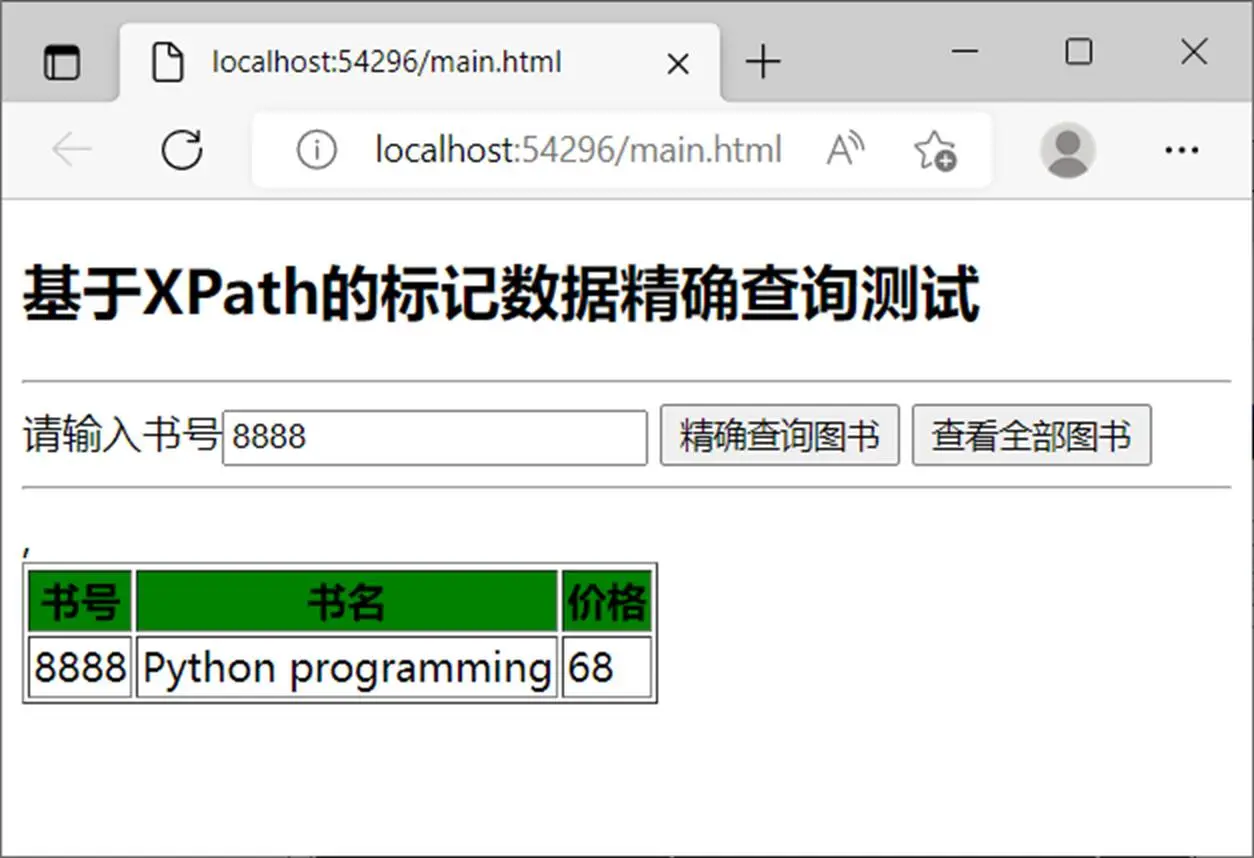
<td>8888</td>
<td>Python programming</td>
<td>68</td>
</tr>
<tr>
<td>8767885</td>
<td>NodeJS</td>
<td>90</td>
</tr>
<tr>
<td>r64547565647689</td>
<td>C++ programming</td>
<td>68</td>
</tr>
<tr>
<td>45634748758478</td>
<td>MongoDB</td>
<td>90</td>
</tr>
<tr>
<td>675665647689</td>
<td>operation system</td>
<td>68</td>
</tr>
<tr>
<td>2342353758478</td>
<td>XML技术</td>
<td>90</td>
</tr>
</table>
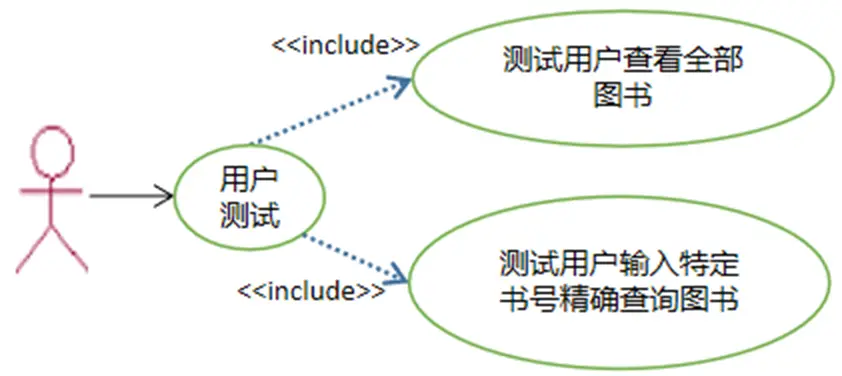
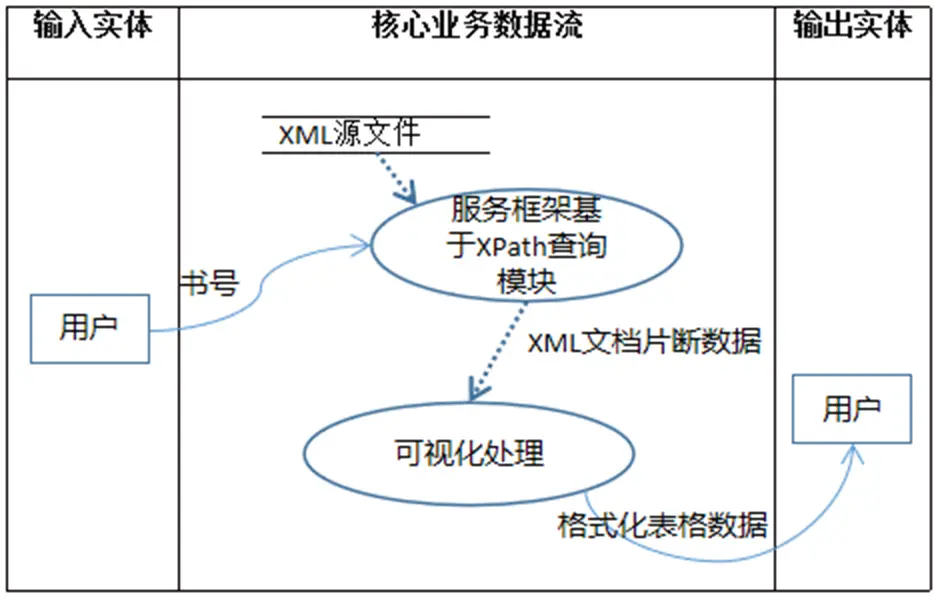
现提出如下设计需求:
- 基于三层架构,调用NodeJS服务,以"书号"为输入参数,实现对图书精确查询。
- 后台需基于xmldom模型借助xpath技术实现。
- 查询结果以表格形式在前端呈现。
14.4 代码实现
14.4.1 主页实现
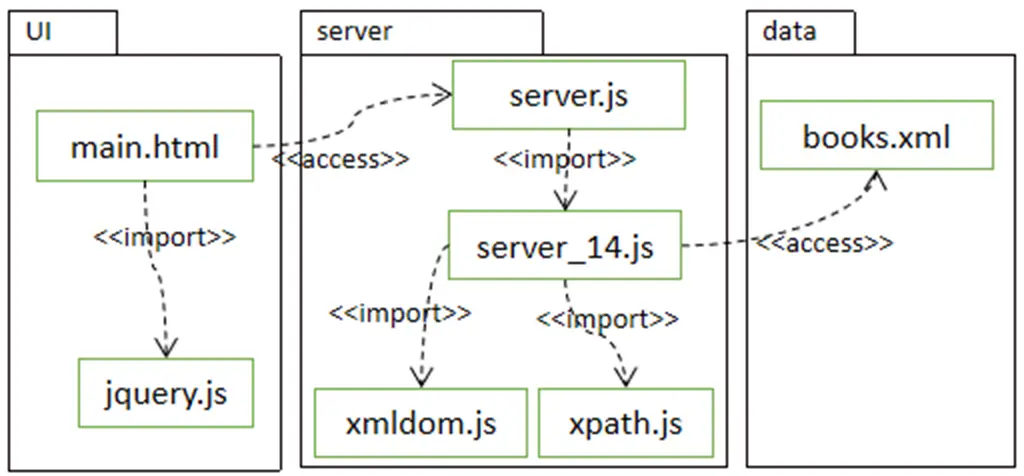
主页文件main.html实现代码如下:
<!DOCTYPE html>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8" />
<title></title>
</head>
<body>
<h2>基于XPath的标记数据精确查询测试</h2>
<hr />
请输入书号<input type="text" id="isbn_input" />
<input type="button" value="精确查询图书" onclick="select_TagData()" />
<input type="button" value="查看全部图书" onclick="view_all()" />
<hr />
<div id="outer_div">
</div>
</body>
</html>
<script type="text/javascript" src="jquery-1.11.1.js"></script>
<script type="text/javascript">
//基于XPath的标记数据精确查询
function select_TagData() {
var book_num = $("#isbn_input").val();
var xhttp = new XMLHttpRequest();
xhttp.open("post", "http://localhost:1017/exeXPath_14?param=" + encodeURIComponent(book_num), true);
xhttp.onreadystatechange = function () {
if (xhttp.status == 200 && xhttp.readyState == 4) {
$("#outer_div").html("<table border='1'>"+xhttp.responseText+"</table>");
}
}
xhttp.send();
}
//查看全部图书
function view_all() {
var xhttp = new XMLHttpRequest();
xhttp.open("post", "http://localhost:1017/viewAll_14", true);
xhttp.onreadystatechange = function () {
if (xhttp.status == 200 && xhttp.readyState == 4) {
$("#outer_div").html( xhttp.responseText);
}
}
xhttp.send();
}
</script>
14.4.2 后台服务实现
1、通用服务实现
// JavaScript source code
//----------------请将这个文件保存为Unicode格式,否则麻烦大大的----------------
const http_obj = require("http");//用于产生服务对象
const fs_obj = require("fs");//读写后台文件
const url_tran_obj = require("url");//解释URL
const server = http_obj.createServer(function (request, response) {
//请求路径处理
var req_str = decodeURI(request.url);
var req_head;
var POS = req_str.indexOf("?");
if (POS == -1) { req_head = req_str; }
else { req_head = req_str.substring(0, POS); }
//设置查询对象
var url_obj = url_tran_obj.parse(req_str, true);
var Q_obj = url_obj.query;
//响应头设置
response.setHeader("Content-Type", "text/plain;charset=utf-8");
response.setHeader("Access-Control-Allow-Origin", "*");//实现跨域访问
response.writeHead(200);
//%%%%%%%%%%%%%----------------begin your code
//初始化所有服务对象
require("./14/server/server_14.js")(request, response, req_head, Q_obj, fs_obj);
//%%%%%%%%%%%%%----------------end your code
});
server.listen(1017);
console.log("Server is running at port 1017...");
2、专用服务实现
文件server_14.js代码:
function server_14(request, response, req_head, Q_obj, fs_obj) {
//执行XPath
if (req_head == "/exeXPath_14") {
var b_isbn = Q_obj["param"];
var b_xpath = "/table/tr[position()=1] | /table/tr[td[1]='" + b_isbn + "']";
var select = require("./xpath");//获取查询函数
var dom = require("./xmldom").DOMParser;//获取DOMParser类
fs_obj.readFile("./14/data/books.xml", "utf-8", function (err, data) {
if (err) { response.end(err); }
else {
var xmldom = new dom().parseFromString(data);
var nodes = select(xmldom, b_xpath);
if (nodes.length == 1) { response.end("未找到相关数据!"); }
else { response.end(nodes.toString()); }
}
});
}
//查看全部图书
if (req_head == "/viewAll_14") {
fs_obj.readFile("./14/data/books.xml", "utf-8", function (err, data) {
if (err) { response.end(err); }
else {
response.end(data);
}
});
}
}
module.exports = server_14
14.4.3 实现效果
查看全部图书如图14.5所示。
精确查询如图14.6所示。